LECTURE 10: Operating Systems
In the previous lecture, we saw how a program that is in the computer memory can be executed step by step. Essentially, this is what happens inside any computer -- even large and complex computers. Of course, most modern computers provide very nice user interfaces with which we all are so familiar. This lecture will provide some of the gaps between our simple microprocessor and our desk-top computers.
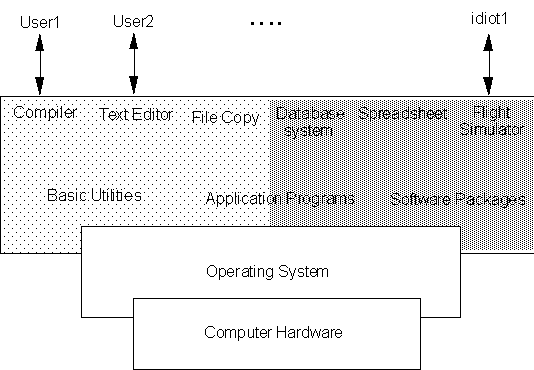
Any computer system can be said to consist of four essential parts: Hardware, Operating System, Application programs, and Users (figure 9.1)
Figure 9.1. Abstract view of a computer system
We have already seen the essential elements of the hardware: The CPU, Memory, I/O devices. One can only interact with the hardware using electric signals. Clearly the user can not perform any meaningful task if he/she is expected to run the computer at such a low level [ in fact, some of the earlier computers required the operator to actually flip switches from the front panel, called the console, entering one instruction at a time !]
The purpose of the operating system is to provide a front-end through which the user can interact with the hardware in relative ease. The main goal of an operating system is therefore to make the computer convenient to use.
Another use of the operating system (OS) is to make the functioning of the computer efficient.
In order to understand what an OS is, we shall study what it does. We shall also study how the OS does what it does.
Essentially, the OS performs resource management. What are the resources ? And what are the management issues ?
Resources:
• The computing power of the CPU
the computer can only perform, say, 12 million instructions per second.
• Memory
The computer has a finite amount of RAM on chips, the hard disc, floppy discs etc.
• I/O devices
Management issues:
Most of the management issues can be better understood if we study the development of computing over the years. Early computers would run a single program (or task). Each program would be loaded onto the computer before it was executed (or run). Inputting the program into the computer took a lot of time, during which the CPU was only reading the instructions from the console, and storing them in sequence in the RAM. It would take the user a few seconds to enter each instruction, while the CPU's job would take a few micro-seconds. The rest of the time, the CPU was unutilized. Besides, if three people wanted to use the computer, they would sign up, for, say few hours of the day when they could come and work on the console. Of course, if the programmer couldn't finish his job in the scheduled time, too bad. Again, if the programmer finished her task in half the time she signed up for, the computer would be idle till the next user showed up.
Later, punched cards were used, on which the programmer could punch out the instruction set (using a card machine), and which could be read into the computer directly. Now each programmer could prepare their stack of punched cards, and give it the operator, whose job was to feed the cards into the computer one stack at a time. When the execution was over for one stack, feed the next stack, and so on.
Figure 9.2. A punched card
Still later, high level languages such as FORTRAN were developed, and with them, compilers. To run the compiler was an interesting procedure: Load the compiler from tape, run the compiler, unload the compiler tape, load the assembler, run the assembler, unload the assembler, load the object code, run the object code.
These early computers were large, and had rows of blinking LED's on the front, indicating the status of the registers. If the blinking stopped, the programmer knew the execution was completed (or, if the code was faulty, the execution had stopped somewhere in the middle.)
Clearly, the entire process was problematic, and non-optimal. The first operating systems were designed to improve the utilization. The solution was simple: break up the memory into several blocks, as shown in figure 9.3.
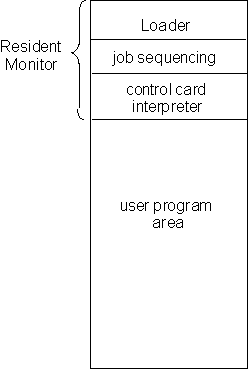
Figure 9.3. Memory layout for the resident monitor
One program was always loaded into memory, and continuously running, the resident monitor. If a user program was loaded into memory, the resident monitor would transfer control to the program. When the program halted, it would return control to the resident monitor, which could then transfer control to the next program.
Even at this stage, interaction with the computer was not via terminals. The user programs were read from punched cards, and utilities like the FORTRAN compiler from tape. to improve efficiency, jobs were run in batches - programs that required the same utility (compiler, e.g.) would be run together, to avoid multiple loading/unloading of the compiler.
In modern computers, I/O is much faster. Usually, the computer reads the executable program from peripheral memory devices such as floppies, or hard disks. Output, if it is to be printed, is transmitted to printers which have large memories to store the output of the computer. In most cases, output is channeled to the monitor and displayed on the screen. Still, compared to the CPU speed, I/O is many magnitudes slower.
Another bottleneck arises due to interactive programs. If the execution requires input from the user, the CPU has to wait a long time while a user enters the input via keyboard (for instance).
To avoid such delays, most operating systems schedule many different processes simultaneously. This is called multiprogramming. Here, many programs are loaded into different parts of the memory. The OS starts executing the first one. If/when the execution requires I/O or some such delay, the CPU immediately switches to the next job and starts it; and so on. The concept is similar to how human managers operates.. consider for example a lawyer handling many cases simultaneously.
Most large computers (such as workstations) operate very fast indeed, and have large memory. So much so, that many different people can work on the same computer simultaneously. You do this, for example, by remote login to the HKUST unix server. In such cases, an extension of multiprogramming is used, called multitasking (or time sharing). Here, the CPU loads all executable jobs into memory, and spends a very small period of time on each job, before moving on to the next job, and so on. Since the CPU works very fast, while user I/O is slow, each of the user's gets the feeling that the CPU is constantly working on their job.
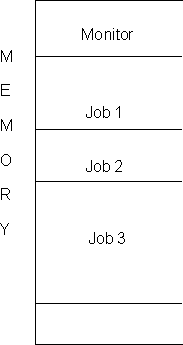
Figure 9.4. Memory layout for the timesharing system
To manage all these tasks, many scheduling issues need to be understood and solved. We shall study these by looking at some of the function of the OS, and the services it provides.
The concept of a Process:
A process is a program in execution. The resources that a process may need include CPU time, memory, files, I/O devices. The OS is responsible for the following activities related to processes:
• creation and deletion of processes;
• scheduling of processes
• providing mechanisms for synchronization and communication
• deadlock handling
Concurrency:
Concurrent processing refers to time-sharing systems. In reality, of course, the CPU is only running one process, but by frequently switching between a bunch of processes, it gives an impression of concurrency.
Apart from supporting multi-user systems, concurrency may have other uses. Sometimes, several users may be simultaneously interested in the same piece of information (for instance, a shared file). The OS must provide concurrent access to such resources.
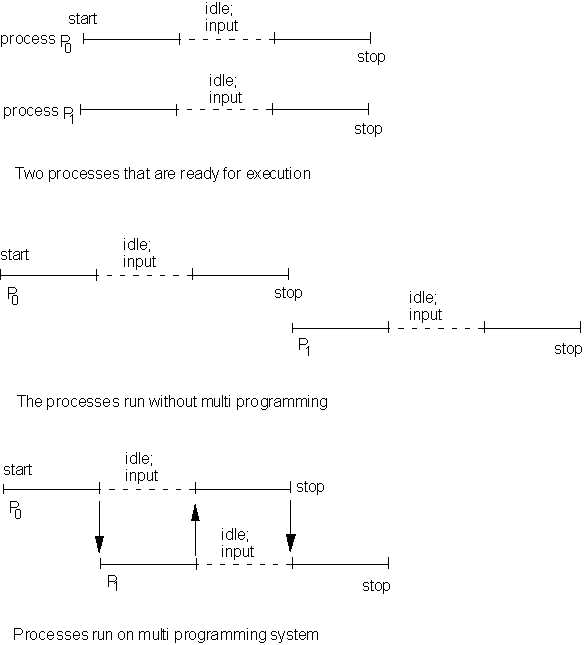
CPU Scheduling:
When multiprogramming, there are several ways in which the multiple tasks can be scheduled. Two of the most common scheduling rules are FCFS (first come first served) and SJF (shortest job first).
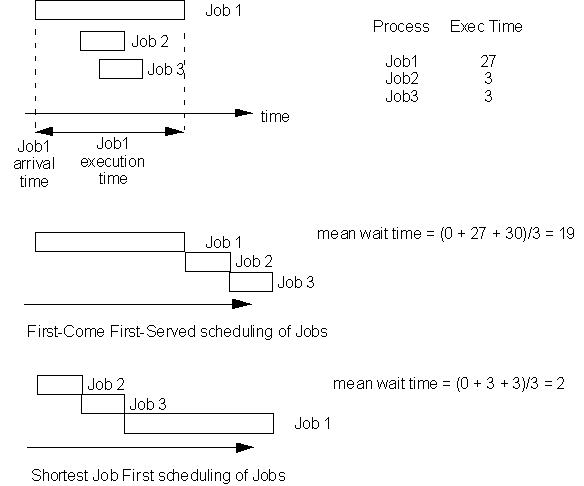
A process that has been requested and has been loaded onto the memory, ready for execution is added on to the process queue. When the CPU completes executing the current process, it looks at the process queue, and depending upon the scheduling rule, selects the next process.
A scheduling rule called round-robin scheduling is used in time-sharing systems. In this system, the CPU spends a short time with each job, then puts it at the end of the process queue, and continues to the next job, and so on. Typically, the time spent on each spurt is 10 millisec - 100 millisec.
Mechanisms for Process Control:
All modern computers perform multitasking. Since many processes are being simultaneously worked upon, the Operating System has to account for controlling the actions of the CPU. The switching from one task to the next is done by generating an interrupt when the time allocated for a given process is over, usually via a CTC (Counter Timer Circuit).
Interrupt based systems Vs Polling systems.
The processor interacts with a number of devices at any given time. While its main task is executing the process which is currently running, it must keep track of many other things. These include incoming messages from the various devices connected to the computer (e.g. network I/O ports, terminals, mouse, etc.).
Why is this important ?
This interaction can be done using either polling, or interrupts.
In polling-based systems, the OS checks each interface in order to see if they have any new data to report. If so, the new data is fetched, and processed. Thus the functioning of the computer is summarized as:
repeat {
for ( allotted time) {
update Prog Counter;
execute Instruction;
}
for (each device) {
poll for data;
process new data;
}
}
The problem with this mechanism of control is that at times when not much data is being received, a lot of computer effort is lost in useless polling. This problem is eliminated by using a different mechanism, interrupt-based control.
An interrupt is, as the name suggests, a signal to the processor to stop whatever it is doing at the current moment, to handle some thing new that has come up. Thus each device that the processor is connected to can generate an interrupt signal when it receives new data.
The functioning of an interrupt-based system can be written in a simplified fashion as:
repeat {
update Program Counter;
execute Instruction;
if Interrupt {
Save current process status;
Jump to subroutine Interrupt Handler;
}
}
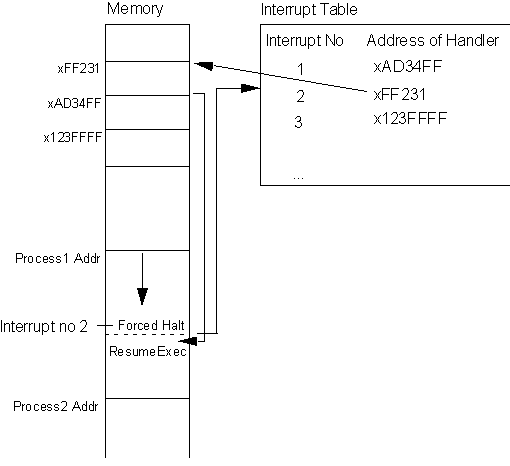
Figure 9.5. Interrupt Handling Procedure
Thus, for performing multi-tasking, the OS can instruct the CTC to generate a specific type of signal after every interval of the allocated burst time for each process. Now the processor can continuously work on its current process till the interrupt from the CTC arrives, at which point, the execution is switched to the next task in the queue.
Similarly, interrupts are generated by each of the devices that are connected to the processor, including the keyboard, mouse, FDC (floppy disk controller), external I/O ports, Hard Disk interface etc.
Two alternative schemes of interrupt handling are commonly used, as shown in figures 9.6 and 9.7.
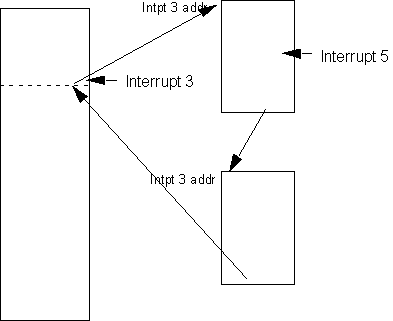
Figure 9.6. Sequential Interrupt Handling
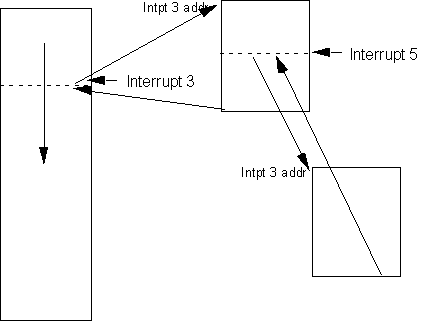
Figure 9.7. Nested Interrupt Handler
An important function of Operating Systems is file management . We shall study this in the context of the most popular operating system of recent times: UNIX.
File Management:
File management is the most visible function of the Operating system. A file is defined as any collection of related information defined by its creator. The functions of an OS involving file management include:
• File/Directory creation
• File/Directory deletion
• File/Directory manipulation
• Provision of protection mechanisms, by controlling access
In UNIX, almost every activity of the computer is controlled via files. A directory is a logical concept, used to create a hierarchy (or classification) of files. Physically, a directory is nothing but a special kind of file itself!
Typically, information about A file is composed of two parts: the data in the file (provided by the creator), and the data about the file (generated by the OS). The latter information includes details such as file name, type, location, size, current position, protection, access times information etc.
Most of the information about the file can be accessed in UNIX by using the command ls.
for instance, typing:
% ls -l /usr/bin/ls
results in the following output:
-rwxr-xr-x 1 root 132352 July 24 1992 /usr/bin/ls
What information does this convey ?
This simple example gives us insight into many aspects of UNIX. Note for instance that "ls" is a file; it is also the name of a function.
What is the mechanism of the interaction between the user and UNIX ? It is a simple "read-execute" loop. Each command typed to the UNIX prompt results in the creation of a process, which is executed. The structure of any command is as follows:
% command [options] [arguments]
Figure 9.8 shows a simplified directory tree of the UNIX system. Most UNIX systems use the same naming conventions for these files.
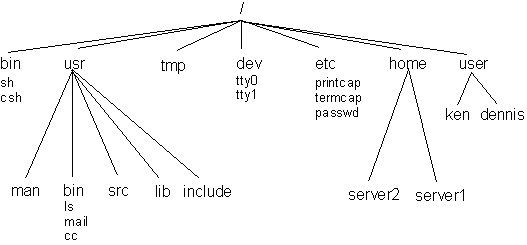
Figure 9.8. A simplified UNIX directory tree