Relational Model Concepts
We have studied the ER diagram as a tool to describe the conceptual model of the Universe of Discourse.
In this lecture, we show a formal method to convert this conceptual model into a logical model called the Relational Model.
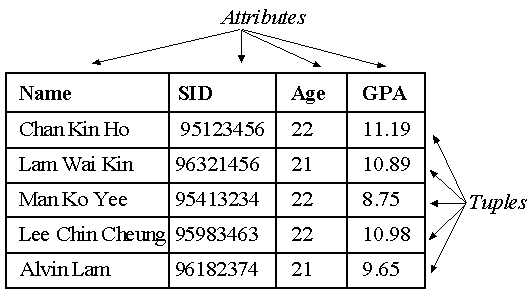
We shall represent a relation as a table of values. Each column of the table has a title or header, called an attribute. Each row is called a tuple.
Terminology
A Relational Schema is denoted by: R( A1, A2, A3, …, An)
Example: STUDENT( Name, SID, Age, GPA)
A tuple with n values is called an n-tuple.
r( R) = { t1, t2, t3, …, tm}
NOTES:
Integrity Constraints
Each relational schema must satisfy the following four types of constraints.
Each attribute A must be an atomic value from dom( A) for that attribute.
Examples of domains could be: integer, real numbers, character, fixed length string, date etc.
Superkey of R: A set of attributes, SK, of R such that no two tuples in any valid relational instance, r( R), will have the same value for SK.
Therefore, for any two distinct tuples, t1 and t2 in r( R), t1[ SK] != t2[SK].
Key of R: A minimal superkey. That is, a superkey, K, of R such that the removal of ANY attribute from K will result in a set of attributes that are not a superkey.
EXAMPLE
CAR( State, LicensePlateNo, VehicleID, Model, Year, Manufacturer)
is a relational schema, with two keys:
K1 = { State, LicensePlateNo}
K2 = { VehicleID }
Both K1 and K2 are superkeys.
K3 = { VehicleID, Manufacturer} is a superkey, but not a key (Why?).
If a relation has more than one candidate keys, we can select any one (arbitrarily) to be the primary key. Primary Key attributes are underlined in the schema:
CAR( State, LicensePlateNo, VehicleID, Model, Year, Manufacturer)
A database normally contains many relational schemas, R1, R2, …, Rn. the set of all relational schemas belonging to the database is called a relational database schema, S.
S = { R1, R2, …, Rn}
Entity Integrity: The primary key attribute, PK, of each relational schema R in S cannot have null values in any tuple. This is because PK is used to identify the individual tuples.
Thus, t[PK] != NULL for any tuple in r( R).
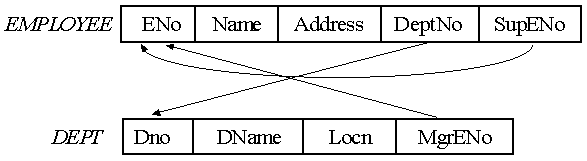
Referential integrity constraints are used to specify the relationships between two relations in a database.
Consider a referencing relation, R1, and a referenced relation, R2. Tuples in the referencing relation, R1, have attributed FK (called foreign key attributes) that reference the primary key attributes of the referenced relation, R2. A tuple, t1, in R1 is said to reference a tuple, t2, in R2 if t1[FK] = t2[PK].
A referential integrity constraint can be displayed in a relational database schema as a directed arc from the referencing (foreign) key to the referenced (primary) key. Examples are shown in the figure below:
ER-to-Relational Mapping
Now we are ready to lay down some informal methods to help us create the Relational schemas from our ER models. These will be described in the following steps:
Choose one relation, say S. Include the primary key of T as a foreign key of S.
Let S be the entity on the N side of the relationship. Include the primary key of T as a foreign key in S.
Create a new relation, P, to represent R. Include the primary keys of both, S and T as foreign keys of P.
Formal Relational Database Design
We have seen the informal procedure to map the ER model into a logical model (relational database schema). How do we know that this is a good schema?
We shall now study the formal theory which can help us to understand (a) what is a good relational database design, (b) why it is good, and (c) how do we design good relational database schemas.
To do so, we shall learn the concepts of Functional dependencies and Normal forms.
We shall use this database for our examples.
To give us some motivation, let us first see what kinds of problems can arise if we fail to design the database properly.
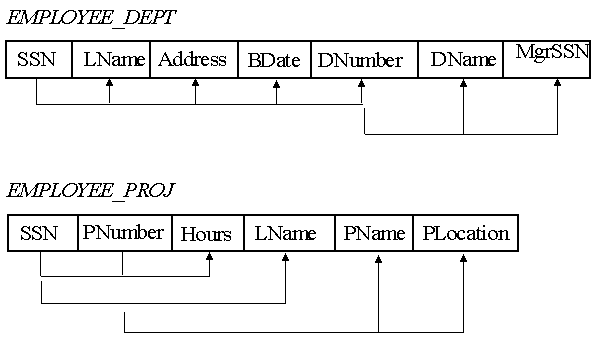
Consider a (poorly) designed database where the Employee and Department information is planned in one table, and the Employee and Project information in another table:
Problems:
( a) Information is stored redundantly -- repeated information => wasted storage.
For example, if 5 employees work for Department number 4, then the department name and manager's SSN for Department 4 is stored 5 times in the table.
( b) Insertion anomalies. When we enter the record for a new employee, we must specify ALL data fields for his department correctly. For example, if a new employee joins Dept 5, then we must ensure that the data entered for Dept 5 in the new record is consistent with the data for Dept 5 in all earlier records of other employees of Dept 5.
( c) Deletion Anomalies. If a dept has one employee working in it, and we delete the information of this employee, then the information of the department is also lost. We may not want this to happen.
( d) Modification Anomalies. If we modify a value, we must make the entire table consistent very carefully. For example, if an employee changes departments from Dept 5 to Dept 4, then his entire record must be changed, not just his DNumber field. If a department changes its manager, the entire table must be scanned and modified.
In general, we should design tables which have the fewest NULL value entries. If an attribute has NULL value very frequently in a table, it should be placed in a separate table (along with the primary key).
As we shall soon see, getting information from a database often requires us to "JOIN" the information from more than one tables, and selecting the correct data out of this joined table. If the database is not designed properly, some JOIN operations will result in wrong (false) data, leading to wrong outputs.
Therefore, the correct database design must guarantee a LOSSLESS JOIN.
One way to alleviate several of these problems is to ensure that our relational database schema is normalized. We shall now study normalization.
Functional Dependencies
Functional dependencies (FDs) are used to specify formal measures of the "goodness" of relational designs.
FDs and Keys are used to define normal forms for relations. FDs are constraints that are derived from the semantics of the universe of discourse (that is, the meaning and inter-relations of the data)
Definition:
A set of attributes functionally determines a set of attributes Y
if the value of X determines a unique value for Y.
This is written as: X -> Y.
The implication of the statement X -> Y is that, for any two tuples, t1 and t2,
if t1[ X] = t2[ X], then t1[ Y] = t2[ Y].
Examples of FD's:
SSN determines employee name
Employee SSN and Project Number determine the Hours per week.
In general, if K is a key of R, then K functionally determines all attributes of R.
Given a set of FDs, we can infer other FDs that will also be true. The rules that are used in this inference are summarized below:
Armstrong's Inference Rules:
A1. (Reflexive). ![]()
A2. (Augmentation). ![]()
(notation; XZ denotes X U Z, the set union of X and Z).
A3. (Transitive). ![]()
A1, A2, and A3 form a complete set of inference rules for FDs. Using these, we can also prove some additional useful inference rules:
A4. (Decomposition). ![]()
A5. (Union). ![]()
A6. (Pseudotransitive). ![]()
Definitions:
Closure of a set, F, of FDs, denoted F+, is the set of all FDs that can be inferred from F.
Closure of a set of attributes, X, with respect to F is the set X+ of all attributes that are functionally determined by X.
X+ can be calculated by repeatedly applying A1, A2 and A3 using FDs in F.
Equivalence of sets of FDs: Two sets of FDs, F and G are said to be equivalent if every FD in F can be inferred from G, AND every FD in g can be inferred from F.
Therefore, F and G are equivalent if F+ = G+.
Minimal set of FDs: A set of FDs is minimal if it satisfies the following conditions.
( a) Every dependency in F has a single attribute for its RHS (right hand side).
( b) We cannot remove any dependency from F, and have a set of dependencies equivalent to F.
( c) We cannot replace any dependency, X -> A, in F with a dependency, Y -> A, where Y is a proper subset of X, and still have a set of dependencies equivalent to F.
In general, we know the following to be true:
Every set of FDs has an equivalent minimal set.
There can be several equivalent minimal sets.
The First Normal Form (1NF)
Disallow any composite attributes, multi-valued attributes, and nested relations.
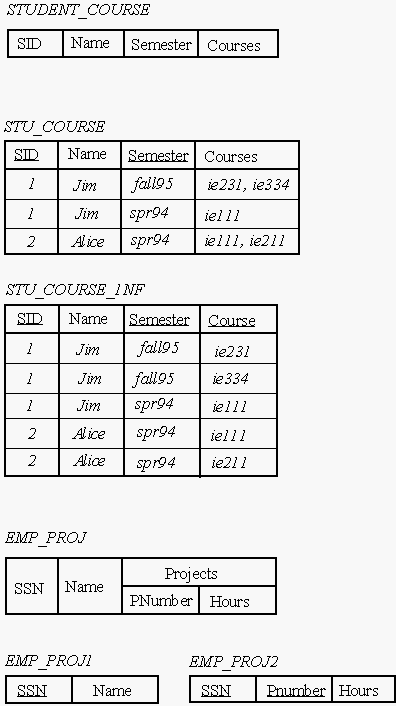
The application of the 1NF is shown in the two examples below. In the first case, The relational schema STUDENT_COURSE has a multi-valued attribute, Courses. A key for STUDENT_COURSE is {SID, Semester}. To get this schema to 1NF, we may convert the multi-valued attribute into a simple attribute, as shown in the schema STU_COURSE. What is a key for STU_COURSE ? Why ?.
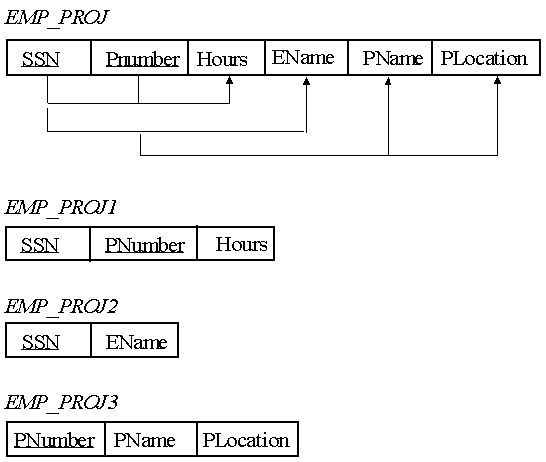
In the second example, the Project information corresponding to each SSN (that is, each Employee), is a composite attribute. In this case, the Projects information corresponding to each SSN is multi-valued. Each employee may work for many projects. Therefore, to get this schema into 1NF, we must break it up into two schemas, EMP_PROJ1 and EMP_PROJ2 as shown.
Note: If the composite attribute is single-valued, then we may just use the components of the attribute in the same schema. For example, EMPLOYEE( SSN, NAME(FName, MInit, LName) ), where NAME is a single valued composite attribute, may be written in 1NF as: EMPLOYEE( SSN, FName, MInit, LName).]
Second Normal Form (2NF)
2NF uses the concepts of FDs and the primary key.
Definitions:
Prime Attribute: An attribute that is a member of the primary key.
Full functional Dependency: A FD, Y -> Z, where the removal of ANY attribute from Y means that the FD will not hold true any more.
Examples:
{SSN, PNumber} -> Hours is a Full FD, since neither {SSN} -> Hours, nor {PNumber} -> Hours is true.
{SSN, PNumber} -> EName is NOT a Full FD, since {SSN} -> EName is also true.
Second Normal Form: A relational schema, R, is in 2NF if every non-prime attribute A in R is fully functionally dependent on the primary key.
The Third Normal Form ( 3NF)
Definitions:
Transitive Functional Dependency: A FD Y -> Z that can be derived from two FDs Y -> X and X -> Z.
Examples:
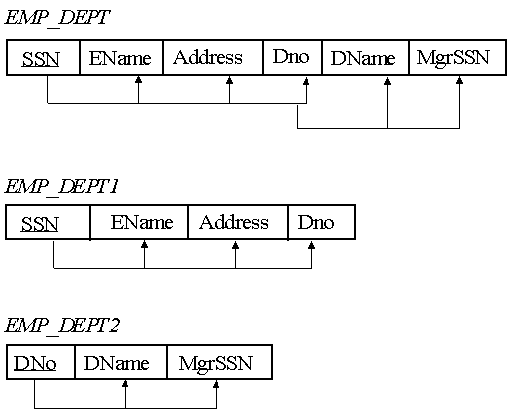
SSN -> MgrSSN is a transitive dependency because:
SSN -> DNumber, and DNumber -> MgrSSN.
SSN -> LName is NOT a transitive dependency, since there is no attribute X, such that SSN -> X, and X -> LName.
Third Normal Form: a relational schema is in 3NF if it is in 2NF, and no non-prime attribute A in R is transitively dependent on the primary key.
Below is an example of a schema that is not in 3NF, and how to decompose it into a pair of 3NF relational schemas.
For most applications, achieving 3NF as defined above will provide an acceptable logical design. However, note that the entire process above is dependent on the (arbitrary) selection of primary keys from all possible candidate keys. There is a broader definition of 3NF which considers the existence of multiple candidate keys.
General Normal Form Definitions
The general 1NF definition is identical to the one before.
A relational schema is in 2NF if it is in 1NF, and if every non-prime attribute A in R is fully functionally dependent on every key of R.
The general 3NF definition requires our earlier definition of superkeys ( a superkey of R is a set of attributes which contain a key of R).
A relational schema R is in 3NF if whenever a FD X -> A holds in R, then
either
X is a superkey of R,
or
A is a prime attribute of R.
Example:
Consider a simplified database for Government records on land sales in different districts.
Each lot of land has a unique ID number for the territory. Within each district, each lot is also assigned a lot#, which is unique in the district.
Further, the tax rate to be paid is determined by the district.
Finally, the government controls the cost of land to be uniform across the territory, so that the price can be determined by the area of the lot.
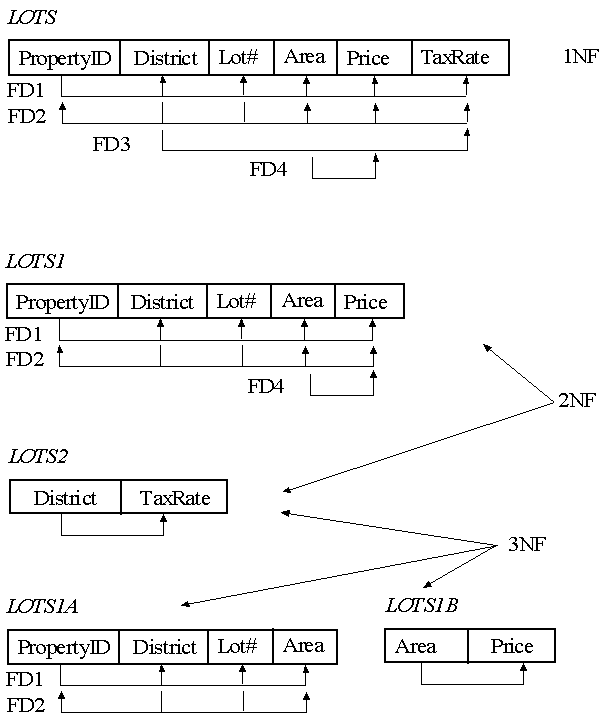
Notice: there are two candidate keys: { PropertyID} and { District, Lot#}.
2NF:
TaxRate is partially dependent upon the candidate key { District, Lot#}, due to FD3.
Hence we break this schema into two parts to achieve 2NF, as shown.
3NF:
LOTS2 is already in 3NF according to the general definition. However, LOTS1 violates the general definition of 3NF, since by FD4, Area -> Price. However, (a) Area is not a superkey of LOTS2; AND, (b) Price is not a prime attribute of LOTS2.
Therefore we further break LOTS1 into LOTS1A and LOTS1B to achieve 3NF.
Acknowledgements. The notes have been based (with minor modifications) on lecture notes of Prof Navathe, as distributed by Dr. Kamal Karlapalem for COMP231, HKUST.