In this lecture, we shall learn the basics of three important issues in all DBMS's.
As we have seen before, we are mainly concerned with two types of transactions in a DBMS:
read (some data from the DB):
step 1. Find the address of the block containing the data
step 2. Copy the block into the main memory (RAM) from the disk
step 3. Get the record which contains the data we need.
and
write (some data to the DB)
step 1. Find address of the disk block containing the data
step 2. Copy the block into main memory (RAM) from disk
step 3. Make the modification of record/Insertion of record as requiredstep 4. Write the block back to the disk.
Why do we need to pay attention to transaction processing ?
The need arises since most practical DB's are used by more than one user,
typically accessing the server from different computers, and perhaps at the
same time.
As we know, most operating systems (including the one on the DB server) are multi-tasking. This means that the computer CPU is normally working on many processes in an interleaved way. Thus, if users A and B execute programs on the same computer at the same time, the CPU will execute a short portion of the process for A, suspend it, process a short portion of process B, suspend it, and return to process A, and so on.
This is true even for two transaction requests sent to a DB server at the same time. What are the problems that can arise due to this ?
The following example shows the different types of problems that can arise:
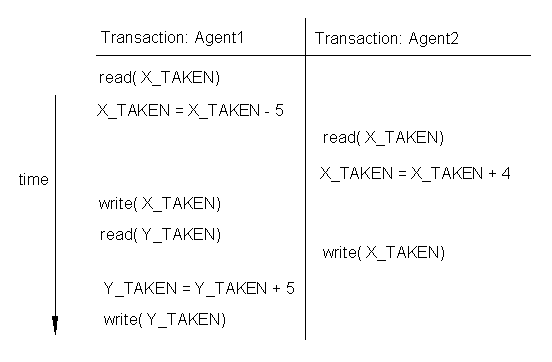
Consider an Airlines database. We are keeping track of seats booked for Flights. The current number of bookings for Flight X is indicated by the value of attribute X_TAKEN.
When a booking of B seats is made, the value of X_TAKEN is increased by B. When a booking of C seats is canceled, the value of X_TAKEN is decreased by C.
Consider two transactions, made by different booking agents at almost the same time. Agent1: cancels bookings for 5 seats on Flight X, and books them for Flight Y.
Agent2: books 4 seats on flight X.
The current value of the X_TAKEN is 80.
The Lost Update Problem:
If the multi-tasking server works on the two transactions as shown above, what is the value of X_TAKEN at the end ?
[ 84 ]
Is this correct ?
No, it should have been 79.
The Temporary Update Problem
Another type of problem may occur when one of the transactions being processed by the server is aborted halfway (that is, the transaction was still not completely processed when it got canceled). Usually, when a transaction is aborted, the DBMS will re-write the initial values that it reads from the DB file.
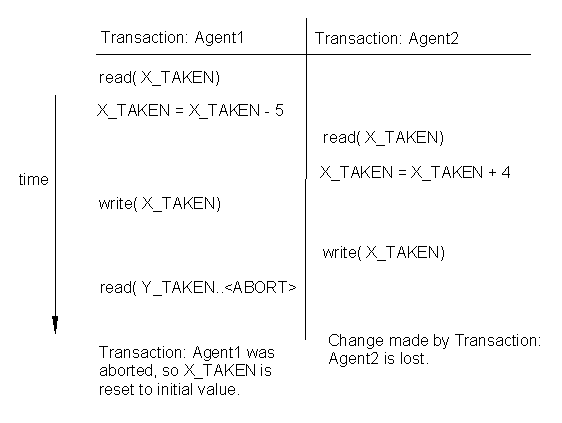
Why did Transaction of Agent1 ABORT ? There can be many reasons:
1. If the computer which Agent1 is using crashed while the transaction was being processed.
2. Illegal operation in transaction: some transactions may have illegal operations (such as Divide by zero, illegal operation, parameters out of valid range etc.) This may cause the entire transaction to fail.
3. User ABORTS (if the Agent1 chooses to abort the transaction by a CONTROL-C).
4. Catastrophic failures: due to electrical outage, power surge, lightning, theft, sabotage etc.
Incorrect Summary Problems
Another type of error due to multi-tasking arises when one transaction requires to compute some result using many records of a table, and while it is getting the required data, another transaction changes part of its data. This is shown in the example below, where one process is computing the sum of the attribute values of a table, while another transaction changes the attribute value for some record:
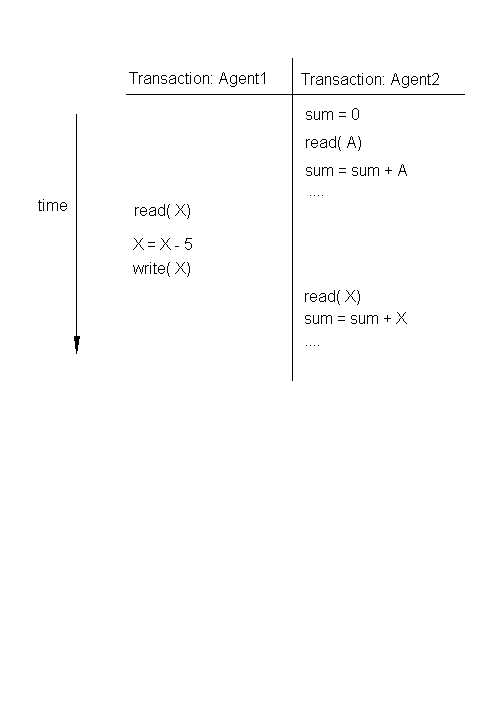
It is therefore essential for a DBMS to have special methods to control how multiple users access the DB values. These methods, or mechanisms, are called concurrency control mechanisms.
Concurrency Control
We shall look at two simple methods of establishing concurrency control: both through the concept of LOCKS.
Binary LOCKS
Every item in the DB (that is, each attribute value) is associated with a one-bit variable that can have a value of Zero (unlocked) or One (locked). The item can be accessed only if the value of the lock equals 0.
In order to make this mechanism work, we need two more actions associated with each transaction: LOCK( X), and UNLOCK( X).
When any transaction requires a read( X), or a write(X) operation, it must first issue a LOCK( X) command. The LOCK(X) command first checks if the value of the LOCK is 0. If so, the LOCK bit is set to 1. Then the data is accessed. After the access is complete, the LOCK is reset to 0 by the UNLOCK( X) command. If the LOCK was 1, then the LOCK process waits till the LOCK value becomes 0 again (HOW ?).
The advantage of Binary LOCKS is that they can be implemented with very little extra storage (one bit per ITEM is enough).
The problem with a Binary LOCK is that it is not very efficient when multiple transactions just need to read the data. In other words, if all processes are only reading data, there is no need for locking it up.
This problem can be avoided by the use of Shared LOCKS.
Shared locks track whether the data is being accessed for reading of writing. By doing so, they can allow/disallow access from to Zero or One write commands, or Zero to many read commands.
To do so, we need three commands: READ_LOCK( X), WRITE_LOCK( X), and UNLOCK( X).
The operation of the three commands is based on the following ideas:
Before a read operation, the item must be read-locked. We have to be careful how to implement the read-lock:
While the read-lock is ON, the item can be used for reading by another transaction; however, it must not be accessible for a WRITE operation ! Therefore we must keep track of how many transactions are currently accessing the item for a read (WHY ?)
The operation is implemented by using an additional integer variable associated with each item, called NO_OF_READS. Before a read operation, we execute READ_LOCK( X).
READ_LOCK( X):
If LOCK is 'write-locked', then WAIT till item is 'unlocked' or 'read-locked'If LOCK is 'unlocked' then set LOCK = 'read_locked'; set NO_OF_READS = 1; precede with the read operation.
If LOCK is 'read-locked', then set NO_OF_READS = NO_OF_READS + 1; proceed with the read operation.
After the read operation is completed, it must be followed by an UNLOCK( X).
Before a write( X) operation, we execute a WRITE_LOCK( X)
WRITE_LOCK( X):
WRITE_LOCK( X) waits until the LOCK value of the item = 'unlocked'. then it sets the LOCK to 'write-locked', and proceeds with the write transaction.
After the write operation is complete, the transaction performs operation UNLOCK(X).
UNLOCK (X):
If the item is 'write-locked', then set the value of LOCK= 'unlocked'If the item is 'read-locked', then set NO_OF_READS = NO_OF_READS - 1;
If NO_OF_READS = 0, then set the value of LOCK = 'unlocked'.
By this mechanism, we ensure that concurrent control is error free in multi-tasking computers.
Data Recovery
As we saw before, there are several reasons for a transaction to ABORT before it is completed. Further, there are cases when a large amount of the data in a DB may be lost due to catastrophic failure ( such as Hard Disk Crash).
It is therefore important for DBMS to enforce several mechanisms to restore the information in the DB. These mechanisms and methods are called recovery methods.
There are two main types of inconsistencies/damage to a DB:
Type 1: When there is a catastrophic error to the Hard Disk, for example, when the Hard Disk crashes (or is physically damaged or lost).
In this case, the only way to recreate the data is if we have a copy of it stored as a backup. In fact, most DBMS are managed by making systematic backups periodically.
During backup, the entire Database and the DB Transaction logs (a record of all transactions done on the DB) are copied to an alternative storage medium (which can be either a magnetic tape, another Hard disk, or a Recordable CDROM.)
If the original DB is lost, the last state which was backed up can be restored. Of course, the changes made since the last backup till the crash time are lost.
Type 2: As mentioned before, there are several reasons for a transaction to fail, which may in turn lead to errors/inconsistencies in the DB. These errors, called non-catastrophic errors, can be corrected. Any good DBMS self-corrects such errors at regular intervals. There are two main mechanisms to do such error recovery:
The Deferred Update methods:
In this method, the physical data on a DB (that is, on the Hard Disk) is not changed until the entire transaction is completed successfully. The successful completion of the transaction is called the COMMIT POINT. During commit, all updates are stored in a file called the DB Log file. After COMMITting, the contents of the log are copied to the DB.
If the transaction fails before reaching the commit point, there is no need to UN-DO any data in the DB. Therefore, this method is called the NO UNDO/ REDO method.
The Immediate Update Methods:
In DBMS's which use this method, changes can be made on the DB while a transaction is still being processed. However, before making any change in the DB, the change is recorded ON the Hard Disk, in a Log file. Only after recording the change in the Log file, is the DB modified at each step.
In this case, if the transaction fails at some intermediate point, then all updates performed BEFORE the fail point must first be rolled back: we need to UNDO those changes. Next, to complete the transaction, we must REDO the entire transaction. Therefore these methods are also called UNDO/REDO methods.
Database Security and Authorization
One of the important decisions made by the DB designer (and administrator) is: what part of the information in a DB should be accessible to which person or group of people. Further, they must decide whether the access for each category of users is merely to read the data, or to change it.
Different DBMS allow very different security mechanisms. We shall take only a brief look at the most basic security methods which are common to many systems.
The overall security of the DB is controlled by the DataBase Administrator (DBA). Any user who wishes to use the facilities of a DBMS must apply to the DBA for an account. The DBA will, upon acceptance of the request, create a new Database (by allocating the required amount of space on the Hard Disk), and assigning a unique name to the DB.
Typically, each DB will also be assigned an OWNER, which is also a user with a login and password, but who controls all access rights to that DB.
Any user who wishes to use an existing DB, must also apply to the DBA. Typically, upon verification from the DB Owner, the DBA will create an account for the user, and allocate a password to her/him.
The DB owner can allow/disallow any user any amount of authority on the Database. This is done by the use of the SQL commands:
GRANT
and
REVOKE
for example, the command issued by the DB-owner for the ieem230 Database in your class:
GRANT ALL TO 'ie_abc';
Will allow the user with login name ie_abc to CREATE Tables, Modify Tables, and of course, Access all information on the Tables created from the account of ie_abc.
Note that user ie_abc has full control of all tables created by him, and can further allow/disallow other users of the ieem230 database to access his Tables:
For example, if ie_abc has a table called "Supplier" created from his account, he may:
GRANT SELECT ON Supplier TO ie_xyz;
or even:
GRANT INSERT, DELETE ON Supplier TO ie_xyz
WITH GRANT OPTION;
The second example shows that ie_abc can allow ie_xyz to change data in ie_abc's Supplier table, AND: ie_xyz can have the option to GRANT similar authority to other users.
If the access must no longer be given, it can be revoked as follows:
REVOKE INSERT ON Supplier FROM ie_xyz;
Note that GRANT and REVOKE can be applied to not only Tables, but also to Views.
Finally: most DBMS's will allow you to GRANT/REVOKE access to specific attributes of a table:
GRANT SELECT ON Supplier( Sname, Snumber) TO ie_xyz;
By selectively using the GRANT and REVOKE commands, the DB owner can usually define several groups of users, each of whom is allowed access only to some of the tables, of the Database.
Modern DBMS's may allow even further levels of security. Some may allow GRANT and REVOKE to be applied to some selected records. Also, most DBMS's will allow further security features such as Data encryption, with the use of additional passwords to un-scramble the data into meaningful values.
This concludes our discussion of Relational Databases.